MERGE в
первую очередь это слияние. Предположим, есть две таблицы с одинаковыми
полями и разными данными. Надо объединить - классический случай обновления
справочника, где справочник-источник находится в OLTP-системе, справочник,
который нужно обновить - в DWH. Нужно сделать так, чтобы в DWH оказались
все данные, с удалением или без удаления старых (исторических данных),
обновились действующие записи и вставились новые.
Оператор
MERGE как нельзя лучше подходит для этой задачи. MERGE появился в Oracle
9i и явялется аналогом UPSERT (UPdate+inSERT). Его использование снижает
расходы на сканирование таблицы (весь DML выполняется за одну операцию) и может
выполнять операцию параллельно при необходимости.
Инструкция MERGE является детерминированной.
Одну и ту же строку целевой таблицы невозможно обновить несколько раз в одной и
той же инструкции MERGE.
Альтернативный
подход состоит в использовании циклов PL/SQL и нескольких инструкций DML.
Однако инструкцию MERGE удобно использовать и проще выразить в виде одиночной
инструкции SQL.
Синтаксис инструкции MERGE
MERGE INTO target_table
USING
source_table_or_view_or_query
ON
search_condition
WHEN MATCHED THEN
UPDATE SET col1 = value1, col2 = value2,...
WHERE <update_condition>
[DELETE WHERE <delete_condition>]
WHEN NOT MATCHED THEN
INSERT (col1,col2,...)
values(value1,value2,...)
WHERE <insert_condition>;
Элементы
синтаксиса:
- Предложение
INTO - задает целевую таблицу, которая обновляется или в которую
выполняется вставка.
- Предложение
USING - идентифицирует источник обновляемых или вставляемых данных; может
быть таблицей, представлением или подзапросом.
- Предложение
ON - условие, по которому операция MERGE выполняет обновление или вставку.
- WHEN
MATCHED | WHEN NOT MATCHED - предписывает серверу, как реагировать на
результаты условия объединения
Принцип действия
Сначала
оператор MERGE выполняет соедиенение left outer join .Основная таблица: data_source,
к ней присоедниняется target_table, и отбираются нужные строки.
Поскольку
это соединение, то можно применять хинты /*+ FULL */, /*+ USE_HASH*/, и
т.д. Прописываются хинты в секции MERGE возле target_table.
Далее
вычисляются предложения WHEN; как только условие удовлетворено, производится
соответствующее действие.
Ключевые
слова WHEN [NOT] MATCH THEN - это управляющая конструкция типа if-else в других
языках.
MERGE
действует так же, как и собственно UPDATE, INSERT или DELETE в отношении target_table,
отличается только синтаксис всей команды. Соотвественно любые триггеры for each
row, определенные на целевом объекте, будут активированы.
Ограничения
- Нельзя обновлять колонки, указанные в ON (ORA-38104: Columns referenced in
the ON Clause cannot be updated)
- Чтобы
вставить все исходные строки в таблицу, можно использовать предикат
постоянного фильтра (constant filter predicate) в условии предложения ON.
Примером постоянного предиката фильтра является ON (0 = 1). С
постоянным предикатом фильтра соединение не выполняется.
- Нельзя
указать DEFAULT при DML через представление (см.далее по тексту
пример).
Создадим
тестовые таблицы. Исходная таблица содержит все строки из представления
ALL_OBJECTS, а целевая таблица содержит примерно половину строк.
CREATE TABLE source_tab AS
SELECT object_id, owner, object_name, object_type
FROM all_objects;
ALTER TABLE
source_tab ADD (
CONSTRAINT
source_tab_pk PRIMARY KEY (object_id)
);
CREATE TABLE
dest_tab AS
SELECT object_id, owner, object_name, object_type
FROM all_objects WHERE ROWNUM <= 35000;
ALTER TABLE
dest_tab ADD (
CONSTRAINT
dest_tab_pk PRIMARY KEY (object_id)
);
begin
DBMS_STATS.gather_table_stats(USER, 'source_tab', cascade=> TRUE);
DBMS_STATS.gather_table_stats(USER, 'dest_tab', cascade=> TRUE);
end;
Производительность
Далее
сравним производительность пяти операций слияния.
Первая
использует прямую инструкцию MERGE. Вторая также использует оператор MERGE, но
построчно. Третья выполняет в цикле FOR обновление и вставку, если обновление
касается нулевых строк. Четвертая выполняет вставку и обновление через FORALL.
Пятая вставляет строку, а затем выполняет обновление в секции EXCEPTION, если
вставка завершается неудачно из-за нарушения уникальности по индексу.
DECLARE
TYPE t_tab IS TABLE OF source_tab%ROWTYPE;
l_tab t_tab;
l_start NUMBER;
BEGIN
l_start := DBMS_UTILITY.get_time;
--- прямой MERGE
MERGE INTO dest_tab a
USING
source_tab b
ON (a.object_id = b.object_id)
WHEN MATCHED THEN
UPDATE SET
owner = b.owner,
object_name = b.object_name,
object_type = b.object_type
WHEN NOT MATCHED THEN
INSERT (object_id, owner, object_name, object_type)
VALUES (b.object_id, b.owner, b.object_name, b.object_type);
DBMS_OUTPUT.put_line('MERGE : ' ||
(DBMS_UTILITY.get_time - l_start) || ' hsecs');
ROLLBACK;
l_start := DBMS_UTILITY.get_time;
--- MERGE построчно
SELECT *
BULK COLLECT INTO l_tab
FROM source_tab;
FOR i IN l_tab.first .. l_tab.last LOOP
MERGE INTO dest_tab a
USING (SELECT l_tab(i).object_id AS object_id,
l_tab(i).owner AS owner,
l_tab(i).object_name AS object_name,
l_tab(i).object_type AS object_type
FROM dual) b
ON (a.object_id = b.object_id)
WHEN MATCHED THEN
UPDATE SET
owner = b.owner,
object_name = b.object_name,
object_type = b.object_type
WHEN NOT MATCHED THEN
INSERT (object_id, owner, object_name, object_type)
VALUES (b.object_id, b.owner, b.object_name, b.object_type);
END LOOP;
DBMS_OUTPUT.put_line('ROW
MERGE : ' ||
(DBMS_UTILITY.get_time - l_start) || ' hsecs');
ROLLBACK;
l_start := DBMS_UTILITY.get_time;
--- построчно в цикле FOR
SELECT *
BULK COLLECT INTO l_tab
FROM source_tab;
FOR i IN l_tab.first .. l_tab.last LOOP
UPDATE
dest_tab SET
owner = l_tab(i).owner,
object_name = l_tab(i).object_name,
object_type = l_tab(i).object_type
WHERE object_id = l_tab(i).object_id;
IF SQL%ROWCOUNT = 0 THEN
INSERT INTO dest_tab (object_id, owner, object_name, object_type)
VALUES (l_tab(i).object_id, l_tab(i).owner, l_tab(i).object_name, l_tab(i).object_type);
END IF;
END LOOP;
DBMS_OUTPUT.put_line('UPDATE/INSERT:
' ||
(DBMS_UTILITY.get_time - l_start) || ' hsecs');
ROLLBACK;
l_start := DBMS_UTILITY.get_time;
--- FORALL
SELECT *
BULK COLLECT INTO l_tab
FROM source_tab;
FORALL i IN l_tab.first .. l_tab.last
UPDATE
dest_tab SET
owner = l_tab(i).owner,
object_name = l_tab(i).object_name,
object_type = l_tab(i).object_type
WHERE object_id = l_tab(i).object_id;
IF SQL%ROWCOUNT = 0 THEN
FORALL i IN l_tab.first .. l_tab.last
INSERT INTO dest_tab (object_id, owner, object_name, object_type)
VALUES (l_tab(i).object_id, l_tab(i).owner, l_tab(i).object_name, l_tab(i).object_type);
END IF;
DBMS_OUTPUT.put_line('FORALL: ' ||
(DBMS_UTILITY.get_time - l_start) || ' hsecs');
ROLLBACK;
l_start := DBMS_UTILITY.get_time;
--- Вставка строки,
и в случае исключения обновление
SELECT *
BULK COLLECT INTO l_tab
FROM source_tab;
FOR i IN l_tab.first .. l_tab.last LOOP
BEGIN
INSERT INTO dest_tab (object_id, owner, object_name, object_type)
VALUES (l_tab(i).object_id, l_tab(i).owner, l_tab(i).object_name, l_tab(i).object_type);
EXCEPTION
WHEN
DUP_VAL_ON_INDEX THEN
UPDATE
dest_tab SET
owner = l_tab(i).owner,
object_name = l_tab(i).object_name,
object_type = l_tab(i).object_type
WHERE object_id = l_tab(i).object_id;
END;
END LOOP;
DBMS_OUTPUT.put_line('INSERT/UPDATE:
' ||
(DBMS_UTILITY.get_time - l_start) || ' hsecs');
ROLLBACK;
END;
Output:
MERGE : 111 hsecs
ROW MERGE : 469 hsecs
UPDATE/INSERT: 432 hsecs
FORALL : 114 hsecs
INSERT/UPDATE: 1419 hsecs
Прямой
оператор MERGE на порядок быстрее, чем его конкуренты. Ближайший по времени -
FORALL, но при росте объема данных, которые нужно будет обновить FORALL будет
отставать все заметнее. Если данных, которые нужно вставить, будет больше, то
FORALL выиграет в этой гонке. Если это неизвестно, то лучше использовать MERGE,
вдобавок его легко можно запустить параллельно.
DELETE
Отдельно
рассмотрим DELETE и его реализацию в Oracle.
Слияние
target и source происходит следующим образом:
В T-SQL и
MSSQL MERGE реализован именно так. В блоке WHEN присутствуют все три элемента
массивов, приведенных на рисунке выше.
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ] [ ...n ]
В ORACLE WHEN NOT MATCHED BY SOURCE отсутствует. DELETE в MERGE возможен, но только как часть UPDATE, как и описано в синтаксисе, и выполняется после UPDATE.
Создадим таблицу-источник на 5 строк.
CREATE TABLE
source AS
SELECT level AS id,
CASE
WHEN MOD(level, 2) = 0 THEN 10
ELSE 20
END AS status,
'Description of level ' || level AS description
FROM dual
CONNECT BY level <= 5;
SELECT * FROM source;
ID STATUS DESCRIPTION
---------- ---------- -----------------------
1 20 Description of level 1
2 10 Description of level 2
3 20 Description of level 3
4 10 Description of level 4
5 20 Description of level 5
5 rows selected.
Создадим
целевую таблицу на 10 строк.
CREATE TABLE
destination AS
SELECT level AS id,
CASE
WHEN MOD(level, 2) = 0 THEN 10
ELSE 20
END AS status,
'Description of level ' || level AS description
FROM dual
CONNECT BY level <= 10;
SELECT * FROM destination;
1 20 Description of level 1
2 10 Description of level 2
3 20 Description of level 3
4 10 Description of level 4
5 20 Description of level 5
6 10 Description of level 6
7 20 Description of level 7
8 10 Description of level 8
9 20 Description of level 9
10 10 Description of level 10
10 rows selected.
Попробуем
обновить часть записей и удалить записи со статусом 10.
MERGE INTO destination d
USING source
s
ON (s.id = d.id)
WHEN MATCHED THEN
UPDATE SET d.description = 'Updated'
DELETE WHERE d.status = 10;Результат:
SELECT * FROM destination;
ID
STATUS DESCRIPTION
----------
---------- -----------------------
1 20 Updated
3 20 Updated
5 20 Updated
6 10 Description of level 6
7 20 Description of level 7
8 10 Description of level 8
9 20 Description of level 9
10 10 Description of level 10
8 rows selected.
Некоторые
строки со статусом 10 не удалились, потому что не попали в выборку. Если строка
не попадает в выборку, указанную в USING, определенное предложением ON, она не
удалится.
Откатим
изменения (пересоздадим таблицы) и посмотрим пример, где оператор DELETE WHERE
может совпадать со значениями строк до операции обновления, а не после. В этом
случае статус всех совпадающих строк изменен на «10», но DELETE WHERE ссылается
на исходные данные - статус проверяется по источнику, а не
по обновленным значениям. В источнике со статусом 10 были строки 2-я и 4-я, они
и были удалены, но 1-я, 3-я и 5-я, у которых после обновления статус =
10, не удалились.
MERGE INTO destination d
USING source s
ON (s.id = d.id)
WHEN MATCHED THEN
UPDATE SET d.description = 'Updated',
d.status = 10
DELETE WHERE s.status = 10; -- смотрим статус в источнике
5 rows merged.
SQL>
SELECT * FROM destination;
ID
STATUS DESCRIPTION
----------
---------- -----------------------
1 10 Updated
3 10 Updated
5 10 Updated
6 10 Description of level 6
7 20 Description of level 7
8 10 Description of level 8
9 20 Description of level 9
10 10 Description of level 10
Переключим DELETE WHERE на целевую таблицу. Удаление произойдет. Останутся
только те строки, которые не попоадают в выборку в USING.
MERGE INTO destination d
USING source sе
ON (s.id = d.id)
WHEN MATCHED THEN
UPDATE SET d.description = 'Updated',
d.status = 10
DELETE WHERE d.status = 10; -- смотрим статус в целевой таблице
посл обновления
5 rows merged.
SELECT * FROM destination;
ID
STATUS DESCRIPTION
----------
---------- -----------------------
6 10 Description of level 6
7 20 Description of level 7
8 10 Description of level 8
9 20 Description of level 9
10 10 Description of level 10
5 rows selected.
Условие в
DELETE в данном случае отфильтровывает уже те строки, которые обновлены: если
до UPDATE значение было равно 20, после апдейта ожидается 10, а фильтр WHERE в
DELETE указан 20, строка не удалится.
Самообъединение
Довольно
частый случай для DELETE (и не только) - самообъединение, когда
target_table участвует в source-подзапросе в качестве основной таблицы.
Пересоздадим
таблицы, но сделаем в них не только разное количество строк, но и не совпадение
по статусам.
DROP TABLE source;
CREATE TABLE source AS
SELECT level AS id,
CASE
WHEN MOD(level, 2) = 0 THEN 10
ELSE 20
END AS status,
'Description of level ' || level AS description
FROM dual
CONNECT BY level <= 5;
DROP TABLE destination;
CREATE TABLE destination AS
SELECT level AS id,
CASE
WHEN MOD(level, 3) = 0 THEN 10
ELSE 20
END AS status,
'Description of level ' || level AS description
FROM dual
CONNECT BY level <= 10;
Запустим следующий тест:
MERGE INTO destination trg
USING (SELECT d.rowid as rwd,
s.status,
s.description
FROM destination d
LEFT JOIN source s on s.id = d.id
) src
ON (trg.rowid = src.rwd)
WHEN MATCHED THEN
UPDATE SET trg.description = src.description,
trg.status = src.status
DELETE WHERE src.status is null; -- фильтр на источник
SELECT * FROM destination;
ID
STATUS DESCRIPTION
----------
---------- -----------------------
1 10 Description of level 6
2 20 Description of level 7
3 10 Description of level 8
4 20 Description of level 9
5 10 Description of level 10
5 rows selected.
Получаем полное соотвествие источнику. Строка WHERE src.status is
null и будет аналогом WHEN NOT MATCHED BY SOURCE
Объединение по ROWID
При
объединении по ROWID обязательно нужно помнить про случаи, когда ROWID может
меняться.
ROWID - это
физический адрес строки, поэтому доступ к строке по ее ROWID является наиболее быстрым
способом.
ROWID
уникален для каждой строки, поэтому его можно использовать в качестве
суррогатного первичного ключа в различных запросах. Oracle гарантирует, что
пока строка существует, ее ROWID не изменится.
Но постоянно
полагаться на ROWID в качестве первичного ключа опасно.
Итак, ROWID
- Обеспечивает
самый быстрый путь доступа к записи.
- Дает
информацию о месте хранении записи (см. описание пакета DBMS_ROWID)
- Уникален
для каждой записи в таблице.
Но ROWID
меняется в результате следующих действий:
- перемещение
таблицы (alter table move)
- сжатие таблицы (alter
table shrink)
- flashback
table to...
- в секционированной
таблице delete+insert в результате различных действий
(импорт\экспорт),
- перемещение
строки в секционированной таблице при изменении значения ее колонок,
входящих в ключ секционирования.
После
удаления строки ее ROWID может быть переприсвоен какой-либо новой строке.
И ROWID
уникален для таблицы, но не для БД в целом.
И не стоит
использовать ROWID в качестве первичного ключа. Однако совершенно
безопасно использовать rowid в комбинации с первичным ключом: обновить набор
данных, где rowid =: x и primary_key =: pk. Эта комбинация позволяет очень
быстро найти нужную строку.
Мутация таблицы
При
самообъеднинении в MERGE можно получить еще одну ошибку: ORA-04091
table owner.table_name is mutating, trigger/function may not see it. Мутация
возникает тогда, когда изменяются строки, которые вычитываются.
Выполним
следующий тест.
MERGE /*+ WITH_PLSQL */ INTO destination trg
USING (WITH FUNCTION change_decrp (p_status IN NUMBER)
RETURN VARCHAR2
IS
return_value VARCHAR2(255);
BEGIN
SELECT description
INTO return_value
FROM destination
WHERE status = p_status
AND ROWNUM = 1;
RETURN (return_value);
END change_decrp;
SELECT id,
change_decrp(status) as description
FROM destination
) src
ON (trg.id = src.id)
WHEN MATCHED THEN
UPDATE SET trg.description = src.description;
Получаем
ORA-04091, хотя ничего не предвещало. Функция находится внутри
USING, и казалось бы, строки до UPDATE уже должны быть вычитаны. Такое
поведение еще встречается в 12с, в 18с это уже исправлено.
Рецепт для
любой мутации - "отбросить" данные на сторону: в коллекцию, в
темповую таблицу. Если сталкиваемся с мутацией в MERGE - оптимальный способ
переписать на BULK COLLECT&FORALL. Если произойдет потеря
производительности, придется с этим мириться, или искать другой вариант -
функционально разбивать на блоки внутри пакета и использовать промежуточную
таблицу.
Часто встречающиеся ошибки
Вернемся к
тому, что MERGE детерминирован. Дубликаты в секции USING недопустимы.
MERGE INTO destination d
USING (SELECT * FROM source
UNION ALL -- сымитируем дубликаты
SELECT * FROM source
)s
ON (s.id = d.id)
WHEN MATCHED THEN
UPDATE SET d.description = 'Updated',
d.status = 10;
Получим ошибку ORA-30926: unable to get a stable set of rows in the
source tables.
Еще одна
ошибка может возникнуть, когда попытаемся удалить записи при наличии
дубликатов.
MERGE INTO destination d
USING (SELECT * FROM source
UNION ALL -- сымитируем дубликаты
SELECT * FROM source
)s
ON (s.id = d.id)
WHEN MATCHED THEN
UPDATE SET d.description = 'Updated',
d.status = 10
DELETE WHERE d.status = 10;
Получим ORA-08006: specified row no longer exists. Ошибка
вполне логичная - заданной строки уже не существует. Такая же ошибка будет в
случае обновления ROWID.
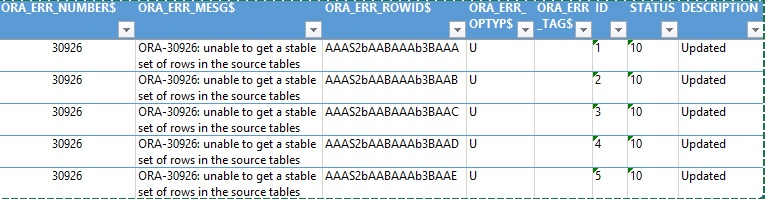
Протоколирование ошибок
Протоколирование
ошибок MERGE можно делать все также с помощью LOG ERRORS.
Cоздаем
таблицу для сохранения записей, отклоненных DML-предложением.
begin
dbms_errlog.create_error_log ('destination','destination_errlog');
end;
destination_errlog - создаваемая таблица для логов
destination - исходная таблица
Выполняем
тест:
MERGE INTO destination d
USING (SELECT * FROM source
UNION ALL -- сымитируем дубликаты
SELECT * FROM source
)s
ON (s.id = d.id)
WHEN MATCHED THEN
UPDATE SET d.description = 'Updated',
d.status = 10
LOG ERRORS INTO destination_errlog REJECT LIMIT
UNLIMITED;
Выполнение в
этом случае завершится без ошибки. Все ошибки запишутся в таблицу логов.
select * from
destination_errlog;
ORA_ERR_NUMBER$
- номер ошибки
ORA_ERR_MESG$ - который показывает сообщение об ошибке
ORA_ERR_ROWID$ - заполняется идентификатором ROWID
ORA_ERR_OPTYP$ - записывается операция при которой возникла ошибка
Updatable View
Ограничения
на обновление представлений такие же как на таблицу, кроме одного: нельзя
указать DEFAULT при DML через представление.
Создадим представление:
create or replace view v_destination as
select id, status, description from destination;
Обновление пройдет прекрасно:
MERGE INTO v_destination
d
USING source s
ON (s.id = d.id)
WHEN MATCHED THEN
UPDATE SET d.description = 'Updated',
d.status = 10
DELETE WHERE d.status = 10;
Но если
пересоздадим представление вот таким образом:
create or replace view v_destination as
select id, status, 'New' as description from destination;
получим ошибку: ORA-01733:
virtual column not allowed here.
Также нужно помнить об прочих ограничениях
обновляемых представлений (
Updatable and Insertable Views).
Спасибо, что
дочитали до конца. Надеюсь, будет полезно.
Источники:







0 Комментарии